
Data Strategy – un concetto trasversale
È da un po’ ormai che L’IT viene considerata un costo e non un investimento, o comunque la priorità è sempre su altro con ben poche eccezioni e solo per aziende dove la tecnologia corrisponde al Core Business.
Secondo questa logica, meno il beneficio è direttamente percepibile come valore, più difficile sarà trovare il budget per l’improvement. In parole povere è più semplice trovare budget per il rinnovo dell’HW, che per l’innesco di una revisione della Data Strategy.
Questo perché è facile quantificare i vantaggi di maggiori prestazioni. Più difficile è far comprendere quali vantaggi porta la revisione di un impianto dati, anche se in realtà i benefici sono maggiori.
Grazie al mio lavoro vedo aziende di tutti i tipi, diverse per tipologia di business e diverse per impianti IT. Andiamo da aziende con mappe 3270 in emulatore di terminale (e giuro che ne ho vista una non più di un paio d’anni fa) ad aziende nate dopo l’avvento del Cloud, che non hanno un data center e sono in grado di trarre vantaggio dalla flessibilità che gli viene offerta. È come dire “Boomers” versus “Nativi Digitali”.
Ma tutti quanti sono accumunati da una certa reticenza nell’affrontare l’argomento Data Strategy. Talvolta sono affascinati dall’aggiungere nuove componenti, ma sono sempre spaventati dal concetto di revisione. Quando si parla di dati, la stratificazione non è mai una buona cosa e aggiungendo un sistema di Big Data ad un parco dati con una gestione di lunga data quello che si ottiene è una sorta di massimo comun denominatore sul quale grava enormemente il peso del punto di partenza, quindi un numero piccolo…
Secondo la mia opinione l’hype seguito dalla caduta libera dei Big Data di qualche anno fa è dovuto proprio a questo: ancora oggi nella maggior parte delle realtà che hanno adottato un Data Lake, che hanno creato laboratori di Advanced Analytics o hanno dati IOT, ci sono difficoltà nel generare un impatto di business.
La mia opinione è che questa situazione si genera quando l’infrastruttura dati esistente non è in grado di interagire correttamente con qualcosa di nuovo e di veloce semplicemente perché non è progettata per farlo, non riesce più ad evolvere.
Mi è capitato di interagire con una realtà che aveva in certi momenti potenziale urgenza di informazioni derivanti da un algoritmo di scoring e quindi ha messo in opera un laboratorio di ML. Peccato che le estrazioni per alimentarlo fossero settimanali e che l’attuale soluzione di data management non fosse in grado di fornire i dati necessari in tempo reale, quindi il risultato era perennemente in ritardo e vecchio allo stesso tempo, un po’ come se il navigatore vi dicesse di girare dopo l’incrocio.
In questo caso il non intervento è sicuramente costoso, ma questo costo compensa gli interventi necessari alla revisione della strategia di data management, finalizzata allo specifico caso d’uso? La risposta è ovviamente no, e qui cominciamo a centrare il problema. A differenza del mondo applicativo, dove una specifica esigenza viene soddisfatta da una specifica innovazione in un ecosistema isolato, un intervento sulla Data Strategy e quindi sulle soluzioni di Data Management, va sempre visto in un’ottica di benefici trasversali.
Per comprendere quali sono i benefici di business che possiamo generare dobbiamo prima comprendere quali sono gli abilitatori tecnologici che un sistema di data management contemporaneo può portare, al fine di indirizzare la strategia in modo corretto. Perché, e anche se è ovvio lo dirò lo stesso, non esiste una strategia panacea di tutti i mali. Ognuno dovrà costruire la propria.
Ecco perché il Cloud con la sua logica di piccoli servizi specializzati porta ad ottenere una soluzione che è al contempo su misura e basata su standard, nella logica dei “Building Block”. Massima resa con il minimo sforzo, a parte ovviamente il cambio di paradigma…
Il cloud è quindi proprio il primo abilitatore tecnologico in una Data Strategy visionaria. Ovviamente non è necessario affrontare un progetto Big Bang, fortunatamente ora possiamo cominciare a pensare in ottica di piattaforma ibrida dove componenti in cloud affiancano e si integrano con componenti on premise. Il Cloud deve quindi essere concepito inizialmente come un’estensione del proprio Data Center. Con l’idea di arrivare alla percezione opposta, cioè le componenti on premise come complemento di un’architettura cloud, che perdono rilevanza nel corso del tempo.
Un concetto che mi è molto caro è quello del “fail first”. Se “capitalizzo” velocemente uno sbaglio e sono in grado di cambiare strada il costo è limitato. Il poter effettuare diverse prove a basso costo garantisce la capacità di individuare la soluzione migliore. Il cloud con le licenze in prova e i contratti brevi, insieme alla logica sviluppo rapido e iterativo, consente quello che l’acquisto di HW e licenze perpetue non hanno mai permesso: provare, seguire strade innovative e non necessariamente consolidate. Poi se non funziona al massimo si spegne tutto.

Purtroppo, vedo solo pochissime aziende in grado di abbracciare questo approccio. Molte si abbarbicano sulle referenze non comprendendo che la situazione attuale ci permette di cercare la propria strada necessariamente diversa da tutte le altre.
Il secondo abilitatore tecnologico è la federazione del dato, un paradigma che piace a tutti, ma che vedo applicare troppo raramente. Proprio perché, contrariamente a quello che sembra, è un concetto molto pervasivo. Non posso fare federazione se i sistemi che concorrono alla definizione di quello che possiamo chiamare “Layer di armonizzazione e accesso” non sono in grado di garantirmi un accesso in lettura massivo o se l’infrastruttura di rete non è adeguata. Ma ancora una volta, in ottica di trasformazione progressiva, questo non deve fermarci. Ci sono soluzioni che consentono di fare piccoli passi, con meccanismi di caching e replica in tempo reale, oltre che di federazione pura, così da ottenere lo stesso risultato finale senza pesare eccessivamente sui sistemi sorgenti. Certo risulta un po’ più costoso, ma se non si comincia non si può innescare il volano della trasformazione.
Il terzo abilitatore tecnologico riguarda le “Trasformazioni Agile”, Possiamo definire il dato un asset aziendale solo se è trasversale, solo se è fruibile in ogni punto del processo, se è in grado di parlare il dialetto di ogni singola applicazione, il dato quindi vene tradotto viene combinato e trasformato per creare KPI o semplicemente informazioni più articolate e complesse. Le trasformazioni sono storicamente un costo notevole che pesa sulla voce Data Management.
Che siano processi ETL Batch, rotte di integrazione che apportano trasformazioni o processi di orchestrazione multi linguaggio con adapter specifici che supportano la trasformazione contestuale al caricamento, tutti quanti hanno in comune il fatto che persistono il dato trasformato. Quando si usano questi strumenti ci sono “best practices” e “bad practices”. Una volta mi fu chiesto di ottimizzare un processo di caricamento di un DWH che sforava la finestra temporale a disposizione e tra i vari processi mi resi conto che riscrivevano dati non soggetti a trasformazione per ben 29 volte con immenso spreco di tempo e spazio considerando i volumi. In questo caso, oltre al costo della persistenza del dato calcolato, c’era anche il costo della persistenza spropositata dei dati temporanei. Il costo della persistenza però non è solo spazio disco e tempo di scrittura, è anche il tempo necessario per fare i test delle procedure di trasformazione e il tempo necessario alla rielaborazione dello storico, tutte le volte che si interviene in modifica. I lunghi tempi necessari per sviluppo-test portano inoltre a stratificare il SW andando in aggiunta invece che a rivedere l’intero processo, e questa è una cosa che va contro la mia forma mentis, che cerca sempre la via più breve e semplice per arrivare allo scopo anche se questo vuole dire smontare tutto. Questo mi ricorda che mentre agli inizi della mia carriera dovevo convincere il project manager di turno che volevo smontare tutto perché mi era venuta un’idea migliore (fail first) e solitamente lui sveniva, quando poi è toccato a me fare il PM ho dovuto convincere i miei collaboratori che tal volta è più efficace traforare un montagna che valicarla girandogli attorno solo hai percorso un terzo della strada.
Tornando a noi, ma se invece di trasformare il dato e persisterlo lo trasformassi nel momento in cui lo leggo? Il concetto è quello dello schema on-read dei Big Data, me se coniugo questo approccio con la federazione e con il quarto abilitatore tecnologico, una piattaforma di Data Mangement In-Memory, che aggiunge la velocità necessaria in fase di lettura del dato, ecco che aggiungendo la flessibilità del cloud ho definito una visione architetturale di massima che potrò specializzare in funzione delle mie peculiarità e della condizione architetturale di partenza.
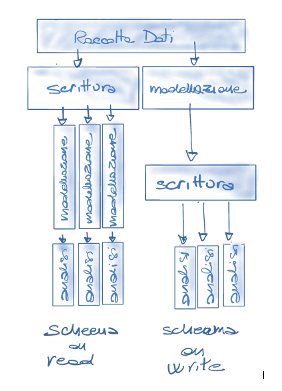
Seguendo questa traccia strategica i benefici attesi sono notevoli.
I dati sono fruibili in real-time nel corretto dialetto sia dalle applicazioni analitiche che da quelle transazionali potenzialmente senza avere la necessità di spostarli o, nel caso di architetture ibride, limitando lo spostamento al push finale verso l’applicazione target che consuma il dato nel formato atteso in tempo reale.
Spesso si pensa che il tempo reale sia un puro esercizio di stile quando si parla di Analytics ma in realtà non è cosi, l’accesso al dato in ottica Schema On Read mi mette nella condizione di poter perseguire un raffinamento continuo sia del tracciato dati analitico con una continua revisione delle strutture dati di front-end, che di rivisitazione dei KPI prodotti, che possono essere realizzati in ottica strategica e quindi integrati anche quando sono di interesse temporaneo come quelli inerenti a specifiche campagne di marketing. Il dato disponibile sempre in real-time, o alla peggio in near-real time, mi permette di applicare algoritmi di ML al momento del bisogno evitando la fase di raccolta dei dati freddi e consentendomi di fare cicli di previsionali in continuo. Lo stesso vale per la pianificazione.

Il tempo di sviluppo compresso, mi consente da un lato di avere un time to market delle informazioni potenzialmente di qualche ora, dall’altro poiché richiede un investimento notevolmente minore mi consente di fare sperimentazione e soddisfare anche le richieste meno prioritarie.
Una revisione della strategia del dato è sicuramente un passo importante, ma a differenza che in passato, oggi non è necessaria un‘implementazione Bing Bang. A fronte di un cospicuo investimento iniziale. I vantaggi offerti dalla strategia possono essere sfruttati già in fase di adozione. Il layer di armonizzazione può nascere lui stesso come oggetto di sperimentazione, sfruttando la flessibilità delle soluzioni cloud e consentendomi di rifinire la strategia strada facendo, aggiungendo o eliminando funzionalità e componenti.
Ci vediamo davanti a una witeboard