
Machine Learning, oltre l’esperimento in laboratorio
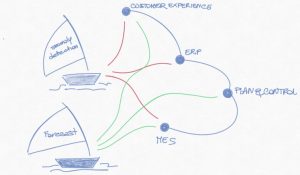
La domanda che tendenzialmente si pone la piccola e media impresa di fronte ad uno scenario del genere, è se il beneficio atteso è davvero superiore all’investimento richiesto, soprattutto a fronte dei tempi necessari per la realizzazione del progetto e pur considerando che quello che verrà realizzato non sarà una specifica soluzione ma una “fucina” per nuove soluzioni. Col problema di coniugare l’approccio di laboratorio con tutta la flessibilità che richiede l’operazionalizzazione della soluzione.
E se provassimo a ribaltare il paradigma?
Se invece di distribuire gli algoritmi con tutto ciò che questo comporta ne centralizzassimo non solo la realizzazione ma anche l’operazionalizzazione?
Se invece di spostare gli algoritmi e gestirne il ciclo di vita delocalizzato fossimo in grado di avere un’infrastruttura centrale in grado di fornire algoritmi as a Service?
D’altra parte, questo è il momento del software as a Service e della logica a microservices. Allora perché non estendere questo concetto anche al mondo del Machine Learning?
Perché non avere un ambiente che centralizza tutti gli engine che ci servono e le rispettive librerie che ci consenta di esporre l’algoritmo in modo che possa essere richiamato dall’applicazione target, ma eseguito centralmente?
Questo sicuramente semplificherebbe e centralizzerebbe tutti gli aspetti di gestione.
Se poi questo concetto di Algoritmo as a Service potesse essere esteso con una componente di data orchestration in grado di mettere a disposizione dell’algoritmo tutti i dati che servono e che sono potenzialmente distribuiti su sistemi eterogenei sia per tecnologia che proprio per metodologia di archiviazione e provisioning delle informazioni, questo introdurrebbe un ulteriore semplificazione della soluzione End2End riducendo notevolmente l’effort progettuale.
Un altro aspetto da non sottovalutare in una soluzione di questo tipo è la disponibilità di metadata e business catalog in grado di mappare il contenuto delle fonti alimentanti; in questo modo chi progetta gli algoritmi sarebbe facilitato nel reperire la fonte più opportuna per ciascuna delle informazioni necessarie.
Nel cambio di paradigma occorre però aggiungere un ulteriore elemento che è un cambio di approccio all’investimento. Il ragionamento che abbiamo esposto finora non può essere sovvenzionato da un singolo progetto, ma deve necessariamente essere introdotto un progetto trasversale che coinvolga potenzialmente diverse line of business e la cui infrastruttura garantirà non solo la messa in produzione dei primi requirements ma anche di quelli che verranno, consentendo al contempo di seguire l’evoluzione dei tool di implementazione.
Le soluzioni cloud in questo caso ci aiutano a contenere il “gradino di ingresso” ossia l’investimento necessario a predisporre l’infrastruttura di partenza, mitigando i rischi e limitando i tempi di sottoscrizione iniziale, pur tenendo presente che per cogliere i benefici di implementazioni di ML e Advanced Analytics è comunque necessario un certo tempo da dedicare all’ottimizzazione dei modelli.
Ci vediamo davanti a una lavagna?